Architecting the Future of Defense
In the high-stakes world of cybersecurity, time isn’t just money; it’s the difference between a minor service hiccup and a business-ending catastrophe. Modern Security Operations Centers (SOCs) are drowning in a sea of data, facing a relentless deluge of alerts from a dozen different security tools. Human analysts are exhausted, alert fatigue is real, and while they are busy manually sifting through the noise, a critical threat might be quietly moving laterally through your network.
The current state of affairs is unsustainable. You cannot hire enough analysts to solve this problem. The solution isn’t more people; it’s a better system. You need to architect automated incident response pipelines.
Why Automation is No Longer Optional
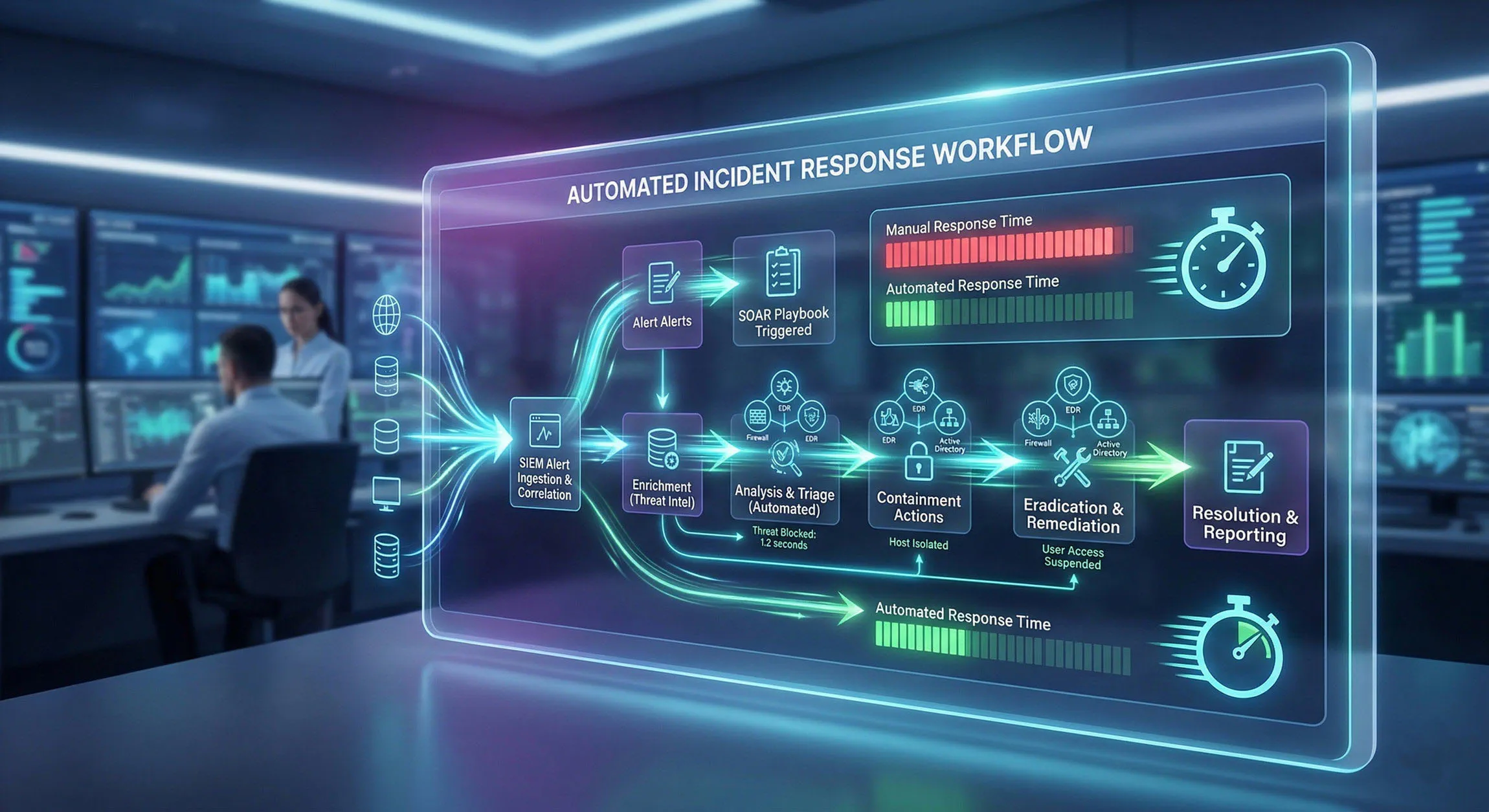
The goal of incident response is to minimize damage and restore normal operations as quickly as possible. The primary metrics we use to measure success are Mean Time to Acknowledge (MTTA) and Mean Time to Remediate (MTTR). Manual processes are inherently slow, prone to human error, and inconsistent.
An automated incident response pipeline, built on Security Orchestration, Automation, and Response (SOAR) principles, transforms your defense strategy from reactive to proactive. Here’s why it’s critical:
-
Lightning-Fast Speed: Automation can reduce response times from hours or days to minutes, significantly slashing both MTTA and MTTR.
-
Consistency and Accuracy: Machines don’t get tired and don’t make transposition errors. Automated actions are executed exactly as defined, every time.
-
Reduced Analyst Burnout: By offloading repetitive “toil”-like gathering logs, checking threat intelligence, and updating tickets-you free your human experts to focus on complex, high-value tasks that require judgement and creativity.
-
Scalability: An automated system can handle a massive influx of alerts without requiring you to linearially scale your headcount.
Velocity Dictates Survival
Time-to-containment is the definitive metric for SOC effectiveness. Human analysts cannot triage the millions of events generated daily by global enterprise networks. Architecting an automated incident response pipeline is mandatory.
Drawing from legacy SOC operations at large telecommunications providers, I mandate a strict coupling of SIEM, SOAR, and Infrastructure as Code. We must transform disjointed alerts into actionable, automated containment workflows.
KQL for High-Fidelity Threat Detection
Effective SIEM architecture relies on precise querying. Generic alerts cause alert fatigue. Security engineers must write highly tuned Kusto Query Language (KQL) scripts to identify anomalous behavioral patterns.
For example, tracking lateral movement requires correlating authentication logs with network traffic. A well-constructed KQL query will detect an anomalous Pass-the-Hash attempt by cross-referencing endpoint EDR telemetry with Active Directory login anomalies. Output these high-fidelity alerts directly into the SOAR platform.
Automating the Response via Python and PowerShell
Once the SIEM detects a verified threat, SOAR playbooks must execute immediately.
- Endpoint Isolation: Execute PowerShell scripts via the SOAR API to instantly isolate compromised Windows endpoints from the domain, leaving only a management tunnel open for forensic analysis.
- Cloud IAM Revocation: Utilize Python automation to revoke AWS STS tokens or Azure AD session cookies the millisecond compromised credentials are detected.
- Malicious IP Blocking: Dynamically update edge firewall blocklists using REST APIs based on continuous threat intelligence feeds.
Structuring the Risk Exception Process
Automation requires a fail-safe. False positives will occur, potentially impacting business SLAs. Establish a formal risk exception process. If a critical business application relies on a vulnerable legacy protocol, business owners must sign off on the accepted risk. Document this within the GRC platform, apply compensating controls (like strict IP whitelisting), and establish a strict remediation timeline. Security supports the business; it does not operate in a vacuum.
Deconstructing the Pipeline: A Phase-by-Phase Architecture
An effective automated incident response pipeline doesn’t just “do things”; it acts as a coordinated system that follows a structured lifecycle. We can deconstruct this architecture into several key phases, primarily leveraging established frameworks like NIST and SANS, and identifying where automation provides the most leverage.
Phase 1: Preparation (The Foundation)
Automation doesn’t work in a vacuum. Before you write a single script, you must have standardized, well-documented, and repeatable manual processes.
-
Architect’s Task: Map out your current workflows. Document roles and responsibilities. Define your “truth” sources for data. Select and integrate your security stack (SIEM, EDR, Firewall, Identity).
-
Automation Opportunity: Use configuration management tools to ensure all endpoints and security devices have standard, up-to-date security configurations. Automatically manage and update a centralized contact list of key personnel.
Phase 2: Detection (The Spark)
The pipeline begins when a monitoring tool detects a potential anomaly.
- Architect’s Task: Configure your SIEM or XDR platform to ingest and correlate logs from diverse sources (network traffic, endpoint activity, cloud audit logs, identity events).
- Automation Opportunity: An anomaly detection system using AI/ML can automatically flag deviant user or system behavior, triggering the pipeline without waiting for a static rule to fire.
Phase 3: Analysis, Enrichment, and Triage (The Intelligent Brain)
This is the most critical phase for automation. It’s where a “noisy alert” is transformed into a “clear incident story.”
- Architect’s Task: Design a system that automatically aggregates relevant diagnostic data from across your stack the moment an alert is triggered.
- Automation Opportunity:
-
Enrichment: Automatically query internal asset databases, identity stores (Active Directory), and external threat intelligence feeds to add context to the alert. Is this user a system administrator? Is this IP address known to be malicious?
-
Triage: Use automated logic to assign a severity score based on business context (e.g., impact on critical assets, type of attack).
-
Prioritization: Automatically route the enriched incident to the correct team or queue.
-
Phase 4: Containment and Eradication (The Action)
Once a threat is validated and prioritized, immediate action is taken to stop its spread.
-
Architect’s Task: Pre-define containment and eradication strategies based on incident type and severity.
-
Automation Opportunity:
-
Short-Term Containment: Automatically execute “safe” containment actions like isolating a compromised host from the network, disabling a compromised user account, or blocking a malicious egress IP on the firewall.
-
Eradication: In some cases, automation can automatically patch a vulnerability or reset credentials. For higher-risk actions, build in a “human-in-the-loop” approval workflow.
-
Phase 5: Recovery (The Restoration)
Restore affected systems to their normal functioning state.
- Architect’s Task: Define procedures for validated, safe restoration of services.
- Automation Opportunity: Automate service restarts, rollback problematic code changes, or deploy security patches to vulnerable systems across the fleet. Continually monitor the restored systems for signs of recurrence.
Phase 6: Post-Incident Activity (The Feedback Loop)
Learn from the incident to prevent future occurrences.
- Architect’s Task: Schedule a formal post-incident review meeting. Use data to identify systemic weaknesses.
- Automation Opportunity:
-
Auto-Documentation: An automated system can capture a full, unalterable timeline of every action taken and decision made during the response, simplifying reporting and audits.
-
Reporting: Automatically generate high-level stakeholder reports and detailed technical summaries.
-
Updating Defenses: Feed lessons learned back into the pipeline by updating detection rules, playbooks, and threat intel sources.
-
Strategic Blueprints: Playbooks vs. Runbooks
A successful pipeline relies on a library of standardized procedures. It is essential to understand the difference between playbooks and runbooks.
| Component | Nature | Scope | Contents |
|---|---|---|---|
| Playbook | Strategic Blueprint | Broad, high-level approach to a type of incident. | Initiating conditions, general process steps (NIST/SANS phases), roles and responsibilities, communication paths, legal/compliance requirements. |
| — | — | — | — |
| Runbook | Tactical Instruction | Narrow, tactical, step-by-step procedure for a specific action. | The literal commands to type, the specific APIs to call, exact criteria for decision-making. These are the code behind your automation. |
| — | — | — | — |
The ideal approach: Create playbooks to govern the “what” and “why” of incident response, and then build executable runbooks that your SOAR platform can run to automate the “how.”
Architect’s Checklist for Success
-
Start Small, Iterate Fast: Don’t try to automate your most complex SEV1 incident on day one. Start with a high-frequency, well-understood, low-risk process, like a known-bad file on a non-critical endpoint or a password reset. Build confidence and gather data.
-
Define Clear Goals: Know what problem you are trying to solve. Is it reducing MTTR? Reducing false positives? Be specific.
-
Integrate Everything: Your pipeline is only as strong as its weakest integration. Use APIs and webhooks to create a cohesive web of security tools.
-
Test Continuously: Do not wait for a real incident to test your automated pipeline. Use tabletop exercises and chaos engineering simulations to validate that your playbooks and runbooks function as intended.
-
Robust Error Handling: Automation will fail. Architect your pipeline to fail gracefully, with clear logging of the failure context and a well-defined escalation path back to a human analyst.
-
Foster Collaboration: Incident response is not just a security problem; it’s a business problem. Cross-functional collaboration with Legal, PR, IT, and Customer Support is essential for building effective communication plans and defining business logic.
Conclusion
Building an automated incident response pipeline is an investment in your organization’s resilience. It’s a journey from chaos to control. By thinking like an architect-structuring your pipeline phase by phase, distinguishing strategy from tactics, and obsessively iterating-you can empower your SOC to act with the speed and precision needed to outpace modern threats. You don’t have to replace your people; you just have to give them the tools to win.