High-Volume Log Ingestion: Optimizing Pipeline Efficiency for Multi-Cloud Architectures
In the modern landscape of distributed, multi-cloud enterprise environments, visibility is the foundational requirement for effective security operations. However, visibility is not achieved simply by collecting more data. Modern organizations are drowning in security telemetry—firewall traffic logs, DNS requests, endpoint EDR data, cloud audit trails, and application logs.
The challenge facing security engineering teams today isn’t data scarcity; it’s data velocity, volume, and variety.
If not managed efficiently, high-volume log data can become an operational bottleneck and a significant financial burden. Raw data lacks operational value. For security teams, the goal is to transform this raw telemetry into actionable intelligence, and this transformation must happen reliably and efficiently, ideally before the data even reaches the Security Information and Event Management (SIEM) platform.
This article provides a technical deep dive into architecting and optimizing high-volume log ingestion pipelines specifically for complex, multi-cloud environments utilizing AWS, Azure, and GCP.
The Architecture of a Modern Ingestion Pipeline
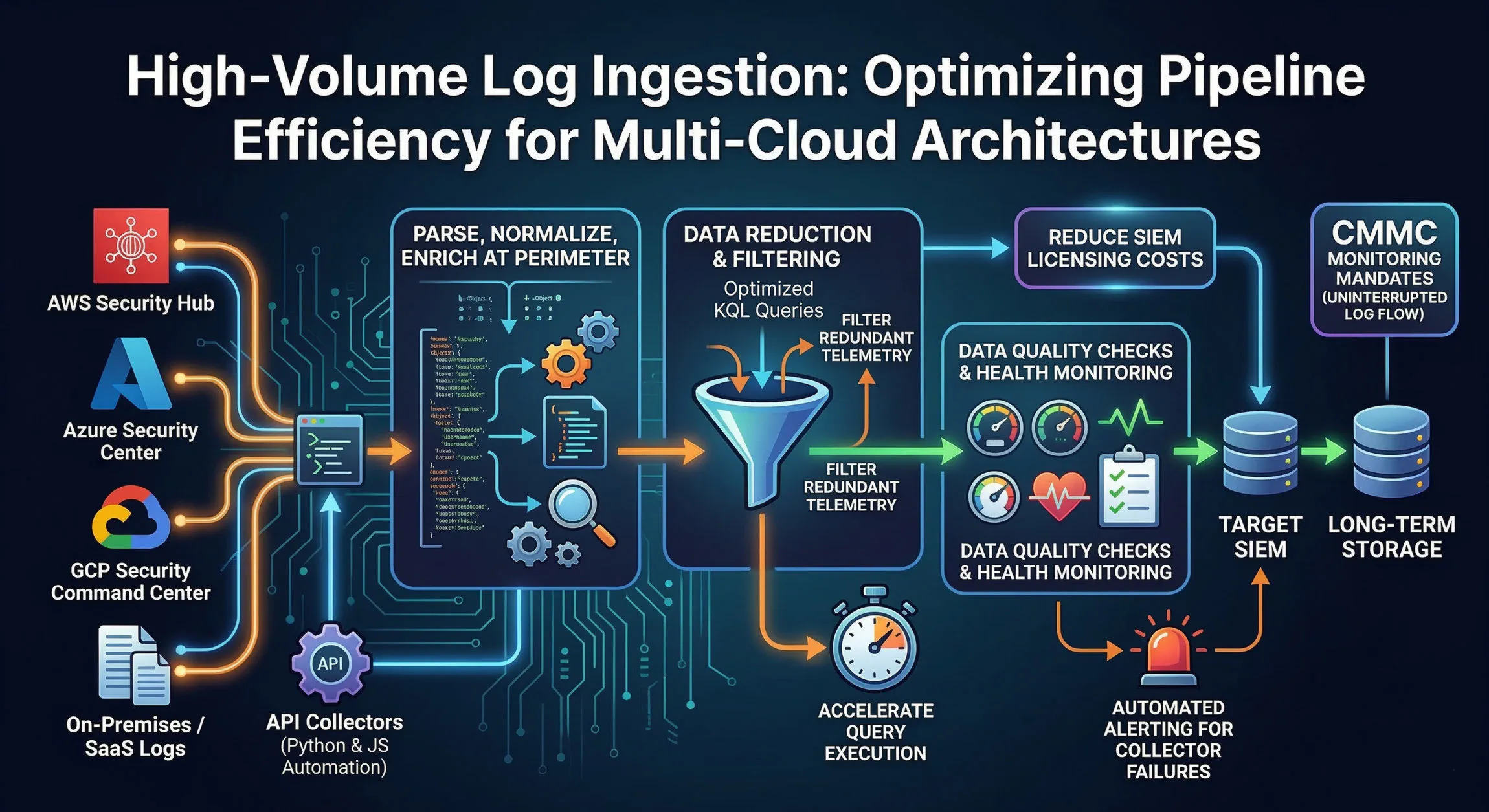
To handle high-volume logs efficiently, a monolithic approach where agents push raw logs directly to a central SIEM is no longer viable. Modern architecture requires a decoupled, staged pipeline.
A resilient ingestion pipeline typically consists of the following stages:
- Collection/Extraction: Pulling logs from disparate sources (cloud providers, on-prem infrastructure, SaaS applications) using various protocols (API, Syslog, HTTP, gRPC).
- Transformation and Normalization: Parsing varied log formats (JSON, CSV, key-value, raw text) and aligning them with a common schema (like the Elastic Common Schema or OSSEM). This is also where data enrichment occurs (e.g., adding GeoIP data to an IP address).
- Data Reduction and Filtering: This is the critical optimization step. Deciding what data is redundant and filtering it out before it gets ingested into billable storage.
- Ingestion/Storage: Writing the optimized, structured data to the final analytical platform (SIEM, Data Lake, or long-term archive).
Leveraging Automation for Collection
Automating log collection is necessary in multi-cloud environments. Security hubs in AWS (Security Hub), Azure (Defender for Cloud), and GCP (Security Command Center) consolidate high-fidelity security alerts and configurations native to their platforms. However, collecting these consolidated logs requires dedicated connectors.
You can build robust API collectors using Python and JavaScript (Node.js) automation to connect directly to these cloud security hubs.
- Python: Excellent for interacting with complex APIs, handling authentication (OAuth2, IAM roles), and data manipulation. Python’s extensive libraries (like
boto3for AWS and the Azure SDK) simplify API interactions. For example, you can write a Lambda function in Python to poll the AWS Security HubGetFindingsAPI regularly. - JavaScript (Node.js): Highly effective for asynchronous, I/O-heavy operations common in collection tasks. Using a serverless function (like Azure Functions) written in Node.js can pull logs from the Azure Monitor Logs API efficiently using its non-blocking event loop.
These automated collectors ensure a steady flow of high-fidelity data, removing the need for operational overhead to maintain manual integrations.
Optimization Strategy: Filtering at the Perimeter
The most direct way to optimize ingestion efficiency is to reduce the volume of data being stored. Traditional SIEM licensing models often charge based on ingestion rate (e.g., GB/day or Events Per Second - EPS). Reducing this volume translates directly to significant cost savings. Furthermore, smaller, cleaner datasets accelerate query execution times, leading to faster detection and response.
Effective data reduction must occur at the perimeter of your architecture, before ingestion into the SIEM. If filtering happens after ingestion, you have already paid for that data.
This requires moving the detection and filtering logic upstream. Consider an organization using Azure Sentinel. Rather than sending all raw Azure Activity Logs directly to Sentinel, the optimal strategy is to use the Azure Monitor logging infrastructure before Sentinel receives the data.
You can write optimized KQL (Kusto Query Language) queries to filter redundant telemetry before storage. In this scenario, you could use a Data Collection Rule (DCR) in Azure Monitor to execute KQL-based filtering rules.
For example, a high-volume source like Windows Security Events generates a vast amount of event ID 4624 (Successful Logon). For many servers, logging every successful logon event provides minimal security value. An optimized KQL filter can be applied to drop these specific event IDs upstream from Sentinel, substantially reducing ingestion volume.
This approach applies across clouds. In AWS, you can use Kinesis Data Firehose with an integrated Lambda function to filter CloudWatch Logs before delivering them to a destination like S3 or an OpenSearch cluster.
Ensuring Reliability: Quality Checks and Alerting
A high-volume ingestion pipeline is complex and subject to failure. APIs time out, authentication tokens expire, data formats change, and network connections drop. Any disruption in log flow creates critical visibility gaps, violating continuous compliance requirements such as those mandated by the Cybersecurity Maturity Model Certification (CMMC) for continuous monitoring.
Dynamic Pipeline Health Monitoring
You must deploy data quality checks to monitor pipeline health dynamically. This involves not only tracking operational metrics (EPS, lag, API errors) but also validating the integrity of the data itself.
- Schema Validation: As data is normalized, apply schema validation checks. Are required fields (timestamp, source IP, event type) present and correctly formatted? Are unknown fields being captured correctly?
- Data Volume Anomalies: Establish baselines for expected ingestion volumes from key sources. Sudden, unexplained drops or spikes in volume often indicate a failure in the collection mechanism or a compromise.
Automated Alerting for Collector Failures
Robust alerting is non-negotiable. If a collector fails, security operations must know immediately. Establish automated alerting for collector failures using monitoring solutions (like Prometheus/Grafana, DataDog, or cloud-native tools like AWS CloudWatch Alarms).
These alerts should trigger notifications (via Slack, PagerDuty, or email) to the appropriate SecOps or DevOps engineering teams. Key metrics to alert on include:
- API Error Rates: Consecutive API errors above a defined threshold.
- Ingestion Lag: A significant increase in the time between event generation and successful ingestion.
- Collector Heartbeats: If an aggregation agent or serverless collector stops sending periodic heartbeat signals, an alert should fire immediately.
Conclusion
Optimizing high-volume log ingestion is no longer an optional tuning exercise; it’s a critical requirement for scalable and cost-effective security operations in multi-cloud environments.
By engineering decoupled ingestion pipelines, leveraging Python and JavaScript automation for collection, and implementing filtering and reduction strategies at the architectural perimeter (such as with optimized KQL queries upstream from the SIEM), organizations can significantly reduce operational costs, improve the performance of their detection and response capabilities, and maintain continuous visibility for compliance. The efficiency of your log ingestion pipeline directly defines the resolution of your defensive visibility.
About the Author Sam Jobes, CISA-CISSP, is a 20-year information security veteran specializing in enterprise security architecture, GRC automation, and building scalable infosec programs for high-growth technology companies.